�����������
1.����
 �㾭������������й�ͬ������������͵©��������˰����Щ����Ŀ϶��ش��������ѿ��ġ���ʵ�ϣ������ʼ���Щ����ʱ�������˻ᲪȻ��ŭ���ܿ��ܶ�Ȼ�ܾ��ش�һЩ����Ϊ���������ⴿ��˽�»�������ܣ��������ء�Ȼ������������ܿ����������йء�����Ϊ֤������һ֧���ӣ����³��������ʹ���������ɲ��ľ��˵İٷֱȡ��ڴ˻����ϣ����ٿ��Ծ����Ƿ���Ҫ����䶾�ƻ���������Ҫѯ�ʾ����йض�Ʒ��ʹ������������跨�ó��йض�Ʒ��ʹ����һ���л�˽������ij�ʵ�Ļش�
�㾭������������й�ͬ������������͵©��������˰����Щ����Ŀ϶��ش��������ѿ��ġ���ʵ�ϣ������ʼ���Щ����ʱ�������˻ᲪȻ��ŭ���ܿ��ܶ�Ȼ�ܾ��ش�һЩ����Ϊ���������ⴿ��˽�»�������ܣ��������ء�Ȼ������������ܿ����������йء�����Ϊ֤������һ֧���ӣ����³��������ʹ���������ɲ��ľ��˵İٷֱȡ��ڴ˻����ϣ����ٿ��Ծ����Ƿ���Ҫ����䶾�ƻ���������Ҫѯ�ʾ����йض�Ʒ��ʹ������������跨�ó��йض�Ʒ��ʹ����һ���л�˽������ij�ʵ�Ļش�
���й���������й����ݵĴ�ͳ�����ǻ��������ܳ�ʵ�ػش�������һ���衣һ��˵����ֻҪ���ⲻ�漰ʹ���ѿ������еĻ��⣬���˵Ļش��dz�ʵ�ġ�����������������ԣ�ʹ�˸е��ѿ������п��ܵò����𰸡�
����ش�����һ��ʹ�����˷��ĵķ�������Ȼ�������ܹ��ƻش��ǡ����ض����͵��������������߲���֪�����������ش�����ݡ����ܱ�����ǰ���ȸ�������������ͳ������Ķ��塣
2.����
ͳ���ƶϿ��Զ���Ϊһ���������Щ�����������ô�һ��������õ���Ϣȥ�ƶ����塣�����Ǿ���ijһΪ���Ǹ���Ȥ�����������п��ܿ��Ƕ���ļ��ϡ������������һ�����ֻ��Ӽ����Ӵ�СΪn�������г�ȡһ����СΪn�����������ÿһ��СΪn������������ͬ��ѡȡ���ܣ��������������̳�Ϊ����������������õ������������������������������ijһ��Ϣ����ֵ��Ϊ������������磬�ٶ�ij�����о�ijѧԺ���ѧרҵѧ����ƽ���ɼ��������GPA�����е�ѧ����GPA�ļ��������壬���ѧרҵ���꼶ѧ����GPA����һ�����������ѧרҵ����ѧ������ߵ�GPA�ͻ��ѧרҵ����ѧ����ƽ��GPA���������������ͳ����Ա��һ����Ҫ�������ô�һ�������ռ�����������������������������������У����ǿ����ڻ��ѧ���꼶ѧ����GPA�����Ϲ��ƻ��ѧ����רҵѧ����ƽ�� GPA��һ��˵�������ѧרҵ���꼶ѧ����ƽ��GPA��ͬ�ڻ��ѧ����ѧ����ƽ��GPA�������������꼶ѧ����GPA�����������һ���֡����ѧרҵ���꼶ѧ����ƽ��GPA�ͻ��ѧרҵ����ѧ����ƽ��GPA�IJ�����dz�������һ�����ӡ�ͳ��ѧ�ҷdz�ע���о����ٳ������İ취��Ȼ�������в����漰����������ij�����о��������Ϊʱ������ĵڶ��������Ƿ������粻�ش�Ͳ���ʵ�ش�֮��ķdz���������ش��Ǽ�������dz�������һ�ַ�����
3.����ش�
������������һ����������ĵ�����������ʱ������Ȼ����һЩ�ر��Ŭ���Ի�ñ����ߵ����Ρ�������ⲻ̫���У���������Ҳ����ٽ�������Ȼ�����������ʹ��һ��������
Warner���飬Ϊ�˼�ǿ������������һ�ַ�����������ش����ַ������ڡ�����й©����Ĵ�ʵ�ʣ����ܽϺú�������˼�롣�����ߵĴ𰸽����ṩ���������µ���Ϣ��ͨ����Щ��Ϣ��ɵ��顣Warner�����ַ���������ı������˹��ơ�
��������������ϸ�ؽ���һ������ش��ٶ�������Ҫ���������о���ij�������������˵ı��������ǼǾ�������������������Ϊ����A��Ҳ��![]() Ϊ��������������A�ı���������ش�Ŀ�����ڲ�ֱ���������Ƿ���������A�����Ƴ�
Ϊ��������������A�ı���������ش�Ŀ�����ڲ�ֱ���������Ƿ���������A�����Ƴ�![]() ����Ϊ���Ŀ�ģ�������Ӧ����һ������Ϊ���װ�ã���֪�������б���
����Ϊ���Ŀ�ģ�������Ӧ����һ������Ϊ���װ�ã���֪�������б���![]() ���Ʊ�������1������ı���Ϊl��
���Ʊ�������1������ı���Ϊl��![]() ���Ʊ�������2���������⣬��û�����������𡣷����ߴ�������ѡȡһ����СΪn�ļ������������������n�����е�ÿһ�����ظ����¹��̡������ߴ�ϴ�õ�������������ѡȡһ�ţ��������ϵ����֣����ֲ�Ҫ�÷����߿�������������ǰ���������⣺
���Ʊ�������2���������⣬��û�����������𡣷����ߴ�������ѡȡһ����СΪn�ļ������������������n�����е�ÿһ�����ظ����¹��̡������ߴ�ϴ�õ�������������ѡȡһ�ţ��������ϵ����֣����ֲ�Ҫ�÷����߿�������������ǰ���������⣺
����1����������A�еij�Ա��
����2���Ҳ�������A�еij�Ա��
��Ҫ������ѡ�����ֻش���Ӧ�����⡣���������������ѡ���Ʊ�������1�����ش��ǡ����ǡ�����������1������˵�ǡ��桱���ǡ��١������Ƶķ�ʽ�������������ѡ���Ʊ�������2�����ش��ǡ����ǡ�����������ġ��桱�͡��١���ע������߽�������ˡ��ǡ��͡����ǡ��Ĵ𰸣�������֪�������ش�����ĸ����⡣Ȼ������ʹֻ֪�����ǡ��Ļش�����������Ҳ�ܹ��Ƴ�![]() ���������������еļǺţ�
���������������еļǺţ�
![]() ����������������A�ı�����
����������������A�ı�����
1��![]() �������в���������A�ı�����
�������в���������A�ı�����
![]() ��ѡȡһ�ű�������1���Ƶĸ��ʡ�
��ѡȡһ�ű�������1���Ƶĸ��ʡ�
1��![]() ��ѡȡһ�ű�������2���Ƶĸ��ʡ�
��ѡȡһ�ű�������2���Ƶĸ��ʡ�
![]() ���ش��ǡ��ĸ��ʡ�
���ش��ǡ��ĸ��ʡ�
m���ش��ǡ��ĸ�����
n�������Ĵ�С��
�ø����۵ļӷ��ͳ˷�������������д�������ߵõ��ش��ǡ��ĸ��ʣ�
P(�ش��ǡ�)��P(ѡȡ��������1�����һش��ǡ�)
��P(ѡȡ��������2�����һش��ǡ�)
��P(ѡȡ��������1����)*P(�ش��ǡ��Oѡȡ��������1����)
��P(ѡȡ��������2����)*P(�ش��ǡ��Oѡȡ��������2����)
������ļǺţ������У�![]() ��1��
��1��
Ϊ�˹���![]() ���������ô𰸡��ǡ�ռ�����ı���������
���������ô𰸡��ǡ�ռ�����ı���������![]() ���ڴ������У���
���ڴ������У���![]() ��m/n����
��m/n����![]() ����
����![]() �����������1���е�
�����������1���е�![]() ��Ϊ����ֵ
��Ϊ����ֵ![]() ���
���
![]() ��
��![]() ��2��
��2��
���о�����ش�ģ�͵�������ǰ�����ǿ���һ�����⡣
��1 һ�о������ǹ���ijѧԺ���꼶ѧ����У�ڼ�ij����ĩ���Ե����ı����������ɼٶ�����ѧ������Ը����������Ϊ�����ԣ��ʺ�������ش��о��������ѧԺ�����꼶����ѡ��200��ѧ���ļ�����������������3/4��������1��l/4��������2����ÿ�������������������⡣
����1����������ڿ��������ס�����2����������ڿ���û���ס�
Ȼ��Ҫ���������ѡȡһ���ƣ������鵽��������Ӧ�ػش��ǡ����ǡ�����200��ѧ�������ظ�������̣��о��ߵõ�60���𰸡��ǡ����÷��̣�2�����������������ڿ������������꼶ѧ���ı�����
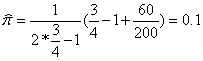
���ԣ����ǹ�����10%�����꼶ѧ���ڿ��������ס�
����ش����������˵Ļش���ʵ�ϣ���������֪�������ش�����ĸ����⡣ֻҪ���������������ʵ�������ͻ��ǿ��
�����߲�Ҫ��ֱ�ӻش����Ƿ�������е�������Ҫ��ش����Ϣ���ھ�����Ϣ��Ҫ��ش�Ķ���ȡ�������װ�����![]() ֵ��
ֵ��![]() ��1/2ʱ�����ڷ�����2��û�ж��壬Ҳ��������Ϣ����
��1/2ʱ�����ڷ�����2��û�ж��壬Ҳ��������Ϣ����![]() ��1��
��1��![]() ��0ʱ������������������Ϣ���ȼ���ֱ��ѯ�ʡ����ڽ���1/2��1����1��1/2�����
��0ʱ������������������Ϣ���ȼ���ֱ��ѯ�ʡ����ڽ���1/2��1����1��1/2�����![]() ֵ�������ṩ�������Ƿ���������A�������õġ����Ǿ��Ե���Ϣ��
ֵ�������ṩ�������Ƿ���������A�������õġ����Ǿ��Ե���Ϣ��
Warner֤���ˣ��ڳ�ʵ�ػش��ǡ��͡����ǡ��ļٶ��£�![]() ����ʵ�������
����ʵ�������![]() ��һ����ƫ���ơ�
��һ����ƫ���ơ�![]() �ķ����ɣ�
�ķ����ɣ�![]() ��3��
��3��
������������Щ��ʵ�����ǿ��Խ���![]() ���������䡣��ֱ��ѯ�ʷ��ij�ʵ��С��100%�ļ����£�Warner�Ƚ���������ƺ�ֱ�ӷ��ʹ��ơ���֤�������������Σ�����شȳ��淽����ֱ��ѯ�ʷ����������ơ������˵������ٶ�����ش��б����߳�ʵ�ػش𣬶����淽����ֱ��ѯ�ʷ����г�ʵ�ش����и���P1��P2(P1������A�еij�Ա��ʵ�ش�ĸ��ʣ�P2�Ƿ�����A�еij�Ա��ʵ�ش�ĸ���)��Warner�Ƚ���������ͳ��淨�ľ����������ԣ�����
���������䡣��ֱ��ѯ�ʷ��ij�ʵ��С��100%�ļ����£�Warner�Ƚ���������ƺ�ֱ�ӷ��ʹ��ơ���֤�������������Σ�����شȳ��淽����ֱ��ѯ�ʷ����������ơ������˵������ٶ�����ش��б����߳�ʵ�ػش𣬶����淽����ֱ��ѯ�ʷ����г�ʵ�ش����и���P1��P2(P1������A�еij�Ա��ʵ�ش�ĸ��ʣ�P2�Ƿ�����A�еij�Ա��ʵ�ش�ĸ���)��Warner�Ƚ���������ͳ��淨�ľ����������ԣ�����![]() ��
��![]() ��P1��P2
����شľ������С�ڳ��淽���ľ�����
��P1��P2
����شľ������С�ڳ��淽���ľ�����
4.���������ģ��
��Warner�ķ����У��������ʾ��漰����������������һ��ʵ���ܻ��������ǵĽ䱸����������֡�Simmons�����һ��Warner�����ĸĽ�������Ϊ����������ڼ�ǿ���������ģ�ͳ�Ϊ���������ģ�͡����ַ������������뷨�����������һ���ؽ�Ҫ�����⣬�����߿����ڸ����ϻ���ø���ȫ����Ϊ�����ش�ʱ�����������й©�������Ϣ���������������״̬���ķ����У����ʹ������������ص����⣬һ�������������йأ���һ���Ƿ����������������ǵ����θоͻ�����
��Simmonsģ���У�������Ա�����ѡȡ����֮һ������лش�
����1����������A�ij�Ա��
����2����������B�ij�Ա��
����A��Ȼ��ʾ���������������ˣ�����B����ѡΪ�����л���˵�����û�������塣ע�⣬����A�ij�Ա�ʸ��ų�����B�ij�Ա�ʸ�֮��Ȼ��һ���˿��Բ��������ߣ�Ҳ������������֮һ�����ѡ������BʱӦ֪����������B�ij�Ա����������ռ�ı���������ѡ������������Ϊ����2��
����2a���������·ݳ�������
����2b���������֤��������һλ����������
����2c����������ڱ�������������һ�죺��һ�����������ġ��塢�����ߡ��ˡ��š����ʮ�죿
����ÿ�����ⶼ�����������ص㣺��������������B�ı���Ҫô����֪�ģ�Ҫô��ǰ���������ƣ�����������·ݵ��˵ı����������˿��ղ����ݹ��ƣ�����֤��������һλ���������ı�����1/2��
����������۲��������ģ�͡���������ѡȡһ����СΪn�ļ���������������߱���Warnerģ����ͬ�����װ�ã�ÿ�������ߴ�ϴ�õ�������������س��һ�ţ��������ϵ����ֻش���Ӧ�����⡣ͬ�������߽��ܵõ����ǡ��롰���ǡ��Ĵ𰸡�Ȼ������������Щ���ݹ��Ƴ���![]() ������
������
������һ���ø����۵Ļ�������д����![]() ��4��
��4��
���![]() �ǻش��ǡ��ĸ��ʣ�
�ǻش��ǡ��ĸ��ʣ�![]() �dz�Ա��������A�ĸ��ʣ�
�dz�Ա��������A�ĸ��ʣ�![]() �dz�Ա��������B�ĸ��ʣ�
�dz�Ա��������B�ĸ��ʣ�![]() ��ѡȡ��������(������1)�ĸ��ʡ��ٶ�
��ѡȡ��������(������1)�ĸ��ʡ��ٶ�![]() ����֪�ģ����ǾͿ��Թ��Ƴ�
����֪�ģ����ǾͿ��Թ��Ƴ�![]() ��ֵ����m�Ǵ�СΪn�������лش��ǡ��ĸ��������ǿ�����
��ֵ����m�Ǵ�СΪn�������лش��ǡ��ĸ��������ǿ�����![]() ��m/n������
��m/n������![]() ���ӷ�����4���н��
���ӷ�����4���н��![]() ���Ϳɵõ�����ֵ
���Ϳɵõ�����ֵ![]() �����
�����
![]() ��
��![]() ��0
��5��
��0
��5��
�����Ⱦ�һ��Ӧ�ò��������ģ�͵����ӣ����о�һЩ��ģ�͵����ʡ�
��2 ���������ijѧԺ����ͬ����������Ů���ı������ָ�Ů�����������������˽�����ܣ���Ը�ش��й����ǵ�����Ϊ�����⡣���ԣ�����Ӧ���ò��������ģ�͵ó�![]() �Ĺ��ơ�����������������⣺
�Ĺ��ơ�����������������⣺
����1�������й�ͬ����������
����2���������֤��������һλ����ż����
���װ����3/4���Ʊ���1��l/4���Ʊ���2���ʼ���СΪ100�ļ�����������õ�18���˻ش��ǡ�����ʱ![]() ����1/2��
����1/2��![]() �Ĺ����ɷ���(5)���������ڣ�
�Ĺ����ɷ���(5)���������ڣ�
![]()
���ԣ����ǹ��Ƹ�ѧԺ��7����Ů����ͬ����������
������ش�һ�������������ģ��Ҳ�������Ը��˵Ĵ𰸵Ľ��͡�Ȼ����������������ij�Ա�ı������Ի��ڸ��˵Ĵ𰸶�����ó���ͬ����������Ҳ��ȫ��֪����������ѡ������⡣���Ժ������ǿ�����ǿ�����������������B�����и��õĺ�������Ϊ����B��һ�������е����壬��������������Ӧ�ܳ�ʵ�ػش����⡣����һ����Warnerģ�Ͳ�һ����Warnerģ���е����������ǻ����ģ���
����Ҳע������̣�5����p��1/2�ж��塣���������ǿ���ʹ���װ�ö�ÿ�����ⶼ����ͬ��ѡȡ���ʡ���p��1/2�ƺ��Ǽ�ǿ��������һ��;����
Abernathy�ͱ��������ɳǵ��˹�����������о��������˲��������ģ��ʹ�õ��ֳ�ʵ�顣���Ƶ���1968���ڼ举Ů�����˹������ı��������߶Բ��������ģ�͵Ŀ�����������Ҫ�����ۡ��ò��������ģ�͵����˹����������ͬʱ������2800����Ů�ʼ��������������⣺
��A�� ���һ���ɷ��ߣ�����˵���Լ��������һ�����ѣ����Ƿ������˹�����������Ϊ���ܳ�ʵ�ػش�����
��B�� �����ű��˻���Ϊ�Ժ��������ֽţ�����ܽҴ����ǻش�����ĸ������𣿣����װ����װ�к�ɫ����ɫ��ĺ��ӹ��ɡ�������ҡ��������ӣ�ע��¶�ں���С���ϵ������ɫ������ɫ������ش���һ�����⣩���ò��������ģ��ǰ�������⣨A����ʹ�������ģ�ͺ��������⣨B����
��ǰһ�����⣬��67�����˸����Ĵ𰸣�17�����˸����϶��𰸣�16�����˲�ȷ�����������������������������ݣ�������ѡ���DZ�Ҫ�ġ������Ǹ�������20���Ŀ϶��𰸣�60���ķ𰸣�20���IJ�ȷ������˵�����˻������Ų��������ģ�͵ġ�
Greenberg�������о��˲��������ģ�͵����ۻ�����֤���˵�![]() ����֪������£����̣�5��������
����֪������£����̣�5��������![]() ��һ����ƫ���ƣ�����Ϊ��
��һ����ƫ���ƣ�����Ϊ��![]() ��6��
��6��
�������ʵ�����ǿ��Լ���![]() ���������䡣
���������䡣
��ƪ����Ҳ��Ϊ���ڷ��������£����������ģ�ͱ�����ش���Ч����ǰ�ߵķ���С�ں��ߵķ��Dowling��Shachtman֤����ֻҪ![]() ѡ�ô�������֮һ������
ѡ�ô�������֮һ������![]() ��
��![]() ��������������
��������������
ֵ��ע����ǣ�����������ģ�ͣ������Ĺ��ƿ��ܻ��Ǹ�ֵ�����1��Ȼ�����Դ����������ֿ������Ǻ�С�ġ���Щ�˻������۹��������Ľ����Ʒ������⡣
5.����شͲ��������ģ�͵�ʹ��
��������IJ���������һЩ��ͬ�Ļ��ڡ���Щ���ڰ�����������������ʵʩ�������ռ������Ľ������ݡ������漰�˳����������Ҫ��һС�������ݡ�����������ּ�ڼ�ǿ�뱻���ߺ����ķ���������һ�ڣ�����Ҫ����ʵ�ʵ�����ʹ������شͲ��������ģ�͵�һЩ��Ҫ��ע�����
�����ἰ���Ƿ����߱�������������ȫ���ⷽ����ԭ�������ĵظ������߽��������÷���������Ҫ�ġ��������������ڷ�������������������һ��˼�룺����֪�����ش�����ĸ����⡣����˼����Ȼ���Լ�ǿ������
�����������������װ�á�װ��Ӧ�����ܼ������鿪ʼǰӦ������������װ�á�������˫��Ŀ�ģ�һ��ʹ����������װ����û�����ֽţ�����ʹ��������������ʹ�ø�װ�á�
��һ����Ҫ��ע���������Ĵ�ʡ�������ʹ��������������ĺ����Ƿdz���Ҫ�ġ����磬����2�У�����1�ʼ�ͬ������Ϊ�����ӡ��й�ͬ��������������˼Ӧ����������������͡�����ҲӦע�⣬���������ʹ����Щ������Ҫ�˷��������ϵĴ�����������⡣
���һ���Dz��������ģ�����ؽ�Ҫ�������ѡ����Щ���⾡���ؽ�Ҫ��ȴ�п�������ǿ���������á����磬�ٶ�ѡȡ�������ǡ����������Ӣ�����𣿡������߿��ܿ���ͨ��һ���˵Ŀ����ж��������Ƿ�����������塣���������ʵ�ͱ����߶����ѡȡ������Ļش𣬷������п����жϳ��ش����Ƿ��������е����塣���ԣ�Ӧ����ѡȡ�ؽ�Ҫ�����⡣
6.�����ϵĽ���
Ӧ����ƪ������õķ�ʽ���ڿ����Ͻ���һ���漰��������ĵ��顣�����Уѧ��������������Ȥ�Ļ��⡣��ѧ����֪ͳ�Ʒ�����ʹ���ǵõ�����ͬ��ij�ʵ�Ļش�ʱ�������˱��ѧϰͳ��ѧ������Ũ�����Ȥ���������֤���Ը߶ȸ�����ѧ��Ŀ��������ش�ʹ��ʱ���ܵĿ����������ǣ�X��ʿ��������������ʶ���ǣ���ô֪���������ж����˳���飿������˳���飬����ô֪�����ش���������⣿���ͳ��ѧ��������������ҿ��ܻ�Ϊ�˶������㹻����Ȥȥѧ��ͳ��ѧ����
�������������Ȥ��������Ϊ��һ��ѧ�ڿ�ʼʱӦ��������ش������ֵ��顣�ڿ����Ͽ����ú��ٵ�ʱ��������ʵ�ʵ��顣�����ϵ�ʱ�䲻������ʦ��ÿ��ѧ����˽�˷��ʡ����Խ�ʦҪѡȡһ������ѧ������ͬʱʹ�õ����װ�á����磬��ѧͳ�Ƶ�ѧ�����ֶ���һ�������������Щ��������������װ�á����ڣ�������ڿ������̿�����ʦ�ںڰ���д���������⣬����ѧ��ѡ��һ����λ�����������ѡ����С��75�Ļش�����1������ͻش�����2����ʦ�����лش��ǡ���ѧ�����֣���һ���������Ϳ�������ù��ơ���һ������ֵ��ʵ��ֵ����Զ�����õġ�ֻҪ��ѧ��ֱ�ӻش���ij�����������������е��������������һ�㡣
��һ����Ȥ���÷�����ѧ���Լ�������ش��������顣Ϊ���Ŀ�ģ������ԣ�ѧ���������Ȿ������ԭ�������ԣ�ѧ������߱������ĸ����ۻ����ͳ����ij������ۡ����и���ĸ�����֪ʶ��ѧ�����ڸ��ߵ���ѧ������������ģ�͡����磬���ǿ��Կ�������n����ʱ����Щģ�ͻᷢ��ʲô�����Ҳ���ԾͲ�ͬ��n��![]() ��
��![]() ��
��![]() ֵ�ȽϹ��Ƶķ��
ֵ�ȽϹ��Ƶķ��
7.����������
1 һ����еġ����Э�ᡱϣ��ȷ����ȥһ������������һ�ξƵĻ�Ա�ı������ֻ�Ա����Ը����������ƣ��������Ǿ���������ش����װ����һ���ƹ��ɣ�0.8���Ʊ���1��0.2���Ʊ���2�������ǣ�
����1����ȥһ��������������һ�ξơ�
����2����ȥһ������û�������ơ�
��100����Ա����������еõ���35�����ǡ��Ĵ𰸡�����Щ���ݣ��������Э���ȥһ������������һ�ξƵĻ�Ա�ı�����
2 ��������1���ҳ�![]() ��95%���������䣬
��95%���������䣬![]() �ǹ�ȥһ���������ƵĻ�Ա�ı���������ʾ������n�ܴ�ʱ��
�ǹ�ȥһ���������ƵĻ�Ա�ı���������ʾ������n�ܴ�ʱ��![]() ������̬���ƣ���ֵΪ
������̬���ƣ���ֵΪ![]() �������ɷ��̣�3����������ʵ��ע�����ǿ��ڷ��̣�3������
�������ɷ��̣�3����������ʵ��ע�����ǿ��ڷ��̣�3������![]() ����
����![]() ������
������![]() �ķ����
�ķ����
3 ���̵�ľ���ϣ�����Ʋ�ϲ����ְ�����Ĺ�Ա�ı����������������������ʹ�ò��������ģ�ͣ�
����1����ϲ����ı�ְ������
����2�������ᱣ�յ��ϵĺ�������һλ��������
����õ�Ӳ�������װ�á���Աת��Ӳ�ң�����õ�������ش�����1������õ�������ش�����2��������ȡ��һ����СΪ300����������������100���϶��𰸡���������̵겻ϲ����ְ�����Ĺ�Ա�ı�����
��������������һ�����������ֻ�����ͳ����Ա���Խ����Щ���⡣
���������������ģ�Ϳ������ֲ���ϵ����������������з��صij�������ٶ������Ĵ�С������Ĵ�СΪС�������ǿ��Լٶ���СΪn�������лش��ǡ�����Ŀ���Ӷ���ֲ����������˵���ش��ǡ�����Ŀ���Ӵ��в���n��![]() ��
��![]() �ǻش��ǡ��ĸ��ʣ��Ķ���ֲ�������Щ��ʵ�����ǿ��Ը�������о���Щģ�͡�
�ǻش��ǡ��ĸ��ʣ��Ķ���ֲ�������Щ��ʵ�����ǿ��Ը�������о���Щģ�͡�
4 ��Warnerģ���У�֤��![]() ��
��![]() ����ƫ���ơ���֤��
����ƫ���ơ���֤��![]() ������ʾ
������ʾ![]() ��
��
5 ��������4��֤��![]() �ķ����ɷ��̣�3����������ʾ��Var
�ķ����ɷ��̣�3����������ʾ��Var![]() ��
��![]() (1��
(1��![]() )/n��
)/n��
6 (a)������5�Ľ��ۣ�֤��![]() �ķ������д��ֱ��ѯ��ģ�͵ķ���ͬһ���������������Ӧ����ĺ͡�ע�⣺��ֱ��ѯ��ģ����������X/n������
�ķ������д��ֱ��ѯ��ģ�͵ķ���ͬһ���������������Ӧ����ĺ͡�ע�⣺��ֱ��ѯ��ģ����������X/n������![]() ,����X�ǻش��ǡ�����Ŀ��n�������Ĵ�С�����ö���ֲ���������E��X��n����
,����X�ǻش��ǡ�����Ŀ��n�������Ĵ�С�����ö���ֲ���������E��X��n����![]() ��Var(X/n)��
��Var(X/n)��![]() (1��
(1��![]() )/n��
)/n��
(b) ������ֱ��ѯ�ʷ�����(������Ը���ʵ�ػش�)������£����Dz�������ش����ɡ�
7 ��![]() ��ʾ
��ʾ![]() �Ĺ��ơ����壺����
�Ĺ��ơ����壺����![]() �������
�������![]() �����������Ҫȷ�����������һ�������ķ�Χ�ڣ��Ƚ�ֱ��ѯ�ʷ�������ش������������������
�����������Ҫȷ�����������һ�������ķ�Χ�ڣ��Ƚ�ֱ��ѯ�ʷ�������ش������������������![]() ��0.5��
��0.5��![]() 3/4������������Ҫ�����ֵ��ʵ��ֵ�������0.05�ڣ��ҳ�ֱ��ѯ�ʷ�������ش��������������
3/4������������Ҫ�����ֵ��ʵ��ֵ�������0.05�ڣ��ҳ�ֱ��ѯ�ʷ�������ش��������������
8 ֤���ڲ��������ģ���У�![]() ����ƫ�ġ�
����ƫ�ġ�
9 �ٶ���Ӧ�ö���ģ�ͣ�������������ͳ����![]() �Ļ����ϵó�
�Ļ����ϵó�![]() ���������䡣����
���������䡣����![]() ��
��![]() �����Ժ���������ô�������ó�
�����Ժ���������ô�������ó�![]() ���������䡣�ҳ�
���������䡣�ҳ�![]() ��95%���������䣬���
��95%���������䣬���![]() �Dz�ϲ����ְ�����Ĺ�Ա�ı������μ�����3����
�Dz�ϲ����ְ�����Ĺ�Ա�ı������μ�����3����
8.����ش����
��һ�������ᱣ�յ��ĺ�������һλ��(�����Dz�ס��û�вμӱ��գ���һ����ҵ绰����ĵ�6λ��)����Ҫ��ش�����ʱ��������������0��l��2��3��4��5��6�ͻش�����A��������������7��8��9�ͻش�����B��
����A�������ڿ�������������
����B�����������7����8��������9����