§1.2 数值计算的误差
用数值方法解决科学研究或工程技术中的实际问题,一般来说,产生误差是不可避免的,根本不存在绝对的严格和精确。但是我们可以认识误差,从而控制误差,使之局限于最小(或尽量小)的范围内。
算法的实现必须在计算机上进行,计算机并不是像一般人想象的哪样可以解决一切问题而不出差错。半个世纪以来计算机带给我们这个世界的诸多烦恼中,误差问题最为突出。小到银行利率的错算,大到导弹的错误发射,除了操作人员的疏忽、机器的故障引起过失误差外,计算机在处理数据过程中还存在计算误差。这主要是计算机机器数所引起的,机器数的特点是有限、离散;这和数学上常用的实数系无限、稠密、连续的特点完全不同。
在2400多年前,古希腊人提出了被称为几何三大问题的古典难题。这说明在历史上,人类就常被误差所困扰。下面问题就是三大难题之一。
立方倍积问题 做一个立方体,使其体积为已知立方体的二倍。
解 不妨设已知立方体体积为1,要做的立方体体积为2,则所做立方体高度应该为![]() 。用计算机计算出
。用计算机计算出![]() ≈1.259 921 049 894 87(15位数),尽管精确度相当高,但仍然是近似值。下面表中列出了对h取前有限位数时,计算所得体积的误差。
≈1.259 921 049 894 87(15位数),尽管精确度相当高,但仍然是近似值。下面表中列出了对h取前有限位数时,计算所得体积的误差。
|
位数 |
高度 |
体积 |
误差 |
|
2 |
1.2 |
1.728 |
2.7200×10--1 |
|
3 |
1.25 |
1.953125 |
4.6875×10--2 |
|
4 |
1.259 |
1.995616979 |
4.3830×10--3 |
|
5 |
1.2599 |
1.999899757799 |
1.0024×10--4 |
|
6 |
1.25992 |
1.99999500019149 |
4.9998×10--6 |
|
7 |
1.259921 |
1.99999976239049 |
2.3761×10--7 |
|
8 |
1.2599210 |
1.99999976239049 |
2.3761×10--7 |
|
9 |
1.25992104 |
1.99999976239049 |
4.7121×10--8 |
|
10 |
|
|
|
由上表可知,计算机机器数的有限位特点使这一问题只能在满足一定的精度条件下解决。误差是无法消除的。
1.2.1 计算机的数系与运算特点
1.
计算机数系
我们所研究的算法都是在计算机上求解的方法,因此应该了解计算机是如何进行数字计算的,这有助于构造和分析各种数值方法。数字运算主要是实数运算,而任一实数都可以表示为
![]() =±
=±![]()
其中 ![]() 为整数,x称为十进制浮点数。一般地,可定义
为整数,x称为十进制浮点数。一般地,可定义![]() 进制浮点数为
进制浮点数为
![]() =±
=±![]()
其中 ![]()
在计算机中,由于机器本身的限制,一般实数只能被表示为
![]() =±
=±![]()
其中 ![]() 这里的t是正整数,是计算机的字长,c为整数,满足
这里的t是正整数,是计算机的字长,c为整数,满足![]() 和
和![]() 为固定整数,对不同的计算机,
为固定整数,对不同的计算机,![]() 是不同的。这样的是x称为t位
是不同的。这样的是x称为t位![]() 进制浮点数,其中c称为阶码,
进制浮点数,其中c称为阶码,![]() 称为尾数,数集
称为尾数,数集
![]() ±
±![]()
![]()
![]() }
}
称为机器数系,它是计算机进行实数运算所用的数系,一般![]() 取2,8,10和16.机器数系F是一个离散的有限集合,分布也不均匀。在F中有一个最大正数M和一个最小正数m,如数系
取2,8,10和16.机器数系F是一个离散的有限集合,分布也不均匀。在F中有一个最大正数M和一个最小正数m,如数系![]() 中,
中,![]() ,
,![]() 若一个实数的绝对值大于M,则计算机产生上溢错误,若绝对值小于m,则计算机产生下溢错误,上溢时计算机中断程序处理;下溢时,计算机将此树以零表示,继续执行程序。上溢、下溢统称为溢出错误。通常,计算机把尾数为0且阶数最小的数表示为数零。
若一个实数的绝对值大于M,则计算机产生上溢错误,若绝对值小于m,则计算机产生下溢错误,上溢时计算机中断程序处理;下溢时,计算机将此树以零表示,继续执行程序。上溢、下溢统称为溢出错误。通常,计算机把尾数为0且阶数最小的数表示为数零。
2. 计算机对数的接收
设实数x是计算机接收的数,则计算机对其的处理方法是:
1) 若![]() ,则计算机按原样接收x;
,则计算机按原样接收x;
2) 若![]() ,但
,但![]() ,则计算机用数系F中最接近x的数
,则计算机用数系F中最接近x的数![]() 表示并记录x。
表示并记录x。
3. 计算机对数的处理
计算机对接收到数主要做加减乘除四则运算,其运算方式是:
1) 加减法――先向上对阶,再运算,后舍入。
例1 设计算机数系为![]() ,
, ![]()
![]()
![]() 是计算机接收到的二数。则此二数做加法的处理过程是:
是计算机接收到的二数。则此二数做加法的处理过程是:
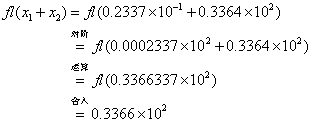
2) 乘除法――先运算,后舍入。
例2
同例1条件,则此二数做乘法的处理过程是:
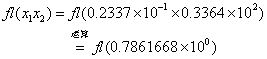
![]()
计算机接收和处理实数的上述特点,往往使得数学上完美的公式在计算机上编程计算时却得不到正确的结果,所以在数值计算的研究中应注意计算机的此种特点。
在计算机数系中,把尾数第一位![]() 的数称为规格化浮点数,用规格化浮点数表示一个实数,具有形式唯一和精度高的特点,但并不是
的数称为规格化浮点数,用规格化浮点数表示一个实数,具有形式唯一和精度高的特点,但并不是![]() 中所有数都能用规格化浮点数表示,如
中所有数都能用规格化浮点数表示,如![]() 就不能用规格化浮点数表示。
就不能用规格化浮点数表示。
1.2.2 误差的来源与分类
在数值计算过程中,估计计算结果的精确度是十分重要的工作,而影响精确度的因素是各种各样的误差,它们可分为两大类:一类称为“过失误差”,即因为疏忽导致误写数字和误用公式等,它一般是由人为造成的,这是可以避免的,故在“数值计算”中我们不讨论它;而另一类称为“非过失误差”,这在“数值计算”中往往是无法避免的,也是我们要研究的,大体有四种类型:模型误差、测量误差、截断误差和舍入误差。例如,计算地球的表面积可以用近似公式:![]()
![]()
![]() 。这其中就包含了各种误差。
。这其中就包含了各种误差。
1 模型误差
用数值计算方法解决实际问题时,首先必须建立数学模型。由于实际问题的复杂性,在对实际问题进行抽象与简化时,往往为了抓住主要因素而忽略了一些次要因素,这样就会使得建立起来的数学模型只是复杂客观现象的一种近似描述,它与实际问题之间总会存在一定的误差。我们把数学模型与实际问题之间出现的这种误差称为模型误差。在上面的近似公式中,把地球表面近似地看成一个球,这就是地球的简单模型,它与地球的实际情况有很大的差别。
2 测量误差
在数学模型中往往包含一些由观测或实验得来的物理量,如电阻、电压、温度、长度等,由于测量工具精度和测量手段的限制,它们与实际量大小之间必然存在误差,这种误差称为测量误差。上面近似公式中地球半径是要经过测量得到,然而无论使用什么工具,其误差是无法避免的。
3 截断误差
由实际问题建立起来的数学模型,在很多情况下要得到准确解是困难的,通常要用数值方法求出它的近似解。例如常用有限过程逼近无限过程,用能计算的问题代替不能计算的问题。这种数学模型的精确解与由数值方法求出的近似解之间的误差称为截断误差,由于截断误差是数值计算方法固有的,故又称为方法误差。例如用函数![]() 的泰勒(Taylor)展开式的部分和
的泰勒(Taylor)展开式的部分和![]() 去近似代替
去近似代替![]() ,其余项
,其余项![]() 就是真值
就是真值![]() 的截断误差。如
的截断误差。如 ![]()
当![]() 很小时,可以取前两项来近似代替
很小时,可以取前两项来近似代替![]() 的计算,即:
的计算,即:![]() ,由泰勒定理可知,这时
,由泰勒定理可知,这时![]() 与
与![]() 的误差是:
的误差是:![]()
在计算中被抛弃了。截断误差的大小,直接影响数值计算的精度,所以它是数值计算中必须十分重视的一类误差。
4 舍入误差
无论用计算机、计算器计算还是笔算,都只能用有限位小数来代替无穷小数或用位数较少的小数来代替位数较多的有限小数。在上面的近似公式中的![]() ,因为是一个无理数,在计算机中无法精确表示,只能取有限位,一般取3.14159,而将后面无穷多位舍弃。不仅无理数,即便是十分简单的有理数如1/3,也只能用有限位的计算机数近似地表示为0.333333(保留6位)。因此在用计算机进行数值计算时,由于计算机的位数有限,在数值计算时只能近似地表示这些数字,由此而产生的误差称为舍入误差。
,因为是一个无理数,在计算机中无法精确表示,只能取有限位,一般取3.14159,而将后面无穷多位舍弃。不仅无理数,即便是十分简单的有理数如1/3,也只能用有限位的计算机数近似地表示为0.333333(保留6位)。因此在用计算机进行数值计算时,由于计算机的位数有限,在数值计算时只能近似地表示这些数字,由此而产生的误差称为舍入误差。
舍入地方法比较多,有收尾法(只入不舍)、去尾法(只舍不入)和四舍五入法等,一般常用人们所熟知的四舍五入法。
当然在计算过程中,这类误差往往是有舍有入的,而且单从一次的舍入误差来看也许是微不足道的,但应当注意的是,在数值计算中,当计算机上完成了千百万次运算之后,舍入误差的积累却可能是十分惊人的,这些误差一经迭加或传递,对精度可能有较大的影响。所以,在做数值计算时,对舍入误差应予以足够的重视。
综上所述,数值计算中除了可以完全避免的过失误差外,还存在难以回避的模型误差、观测误差、截断误差和舍入误差。显然,四类误差都会影响计算结果的准确性,而在这四种误差来源的分析中,前两种误差是客观存在的,称为固有误差,而固有误差往往是计算工作者不能独立解决的,是需要与各有关学科的科学工作者共同研究的问题;后两种误差是由计算方法所引起的,称为计算误差,计算误差将是数值计算方法的主要研究对象。因此,在本课程中,主要研究截断误差和舍入误差(包括初始数据的误差)对计算结果的影响,讨论它们在计算过程中的传播和对计算结果的影响,并找出误差的界,对研究误差的渐近特性和改进算法的近似程度具有重大的实际意义。
1.2.3 绝对误差与相对误差
在不同的场合下,表示近似数精确度的方法各有不同,下面介绍数值运算中误差的基本概念。
1
绝对误差与绝对误差限
定义![]() 是精确值
是精确值![]() *的近似值,则称:E(
*的近似值,则称:E(![]() )=
)=![]() *-
*-![]() 为近似值
为近似值![]() 的绝对误差,简称误差。
的绝对误差,简称误差。
应当注意的是,绝对误差E(![]() )不是误差的绝对值,它是可正可负的,当E(
)不是误差的绝对值,它是可正可负的,当E(![]() ) >0时,称
) >0时,称![]() 为“弱近似值”或“亏近似值”,当E(
为“弱近似值”或“亏近似值”,当E(![]() )<0时,称
)<0时,称![]() 为“强近似值”或“盈近似值”。而误差的绝对值
为“强近似值”或“盈近似值”。而误差的绝对值![]() 是一个非负值,它的大小标志着
是一个非负值,它的大小标志着![]() 的精确程度,
的精确程度,![]() 越小说明
越小说明![]() 的精确程度越高。
的精确程度越高。
一般来说,精确值![]() *是不知道的,因而E(
*是不知道的,因而E(![]() )也就无法求出。但在实际测量中,可以根据具体情况估计出
)也就无法求出。但在实际测量中,可以根据具体情况估计出![]() 的某个上界,即存在一个适当的正数
的某个上界,即存在一个适当的正数![]() ,使得:
,使得:![]() =
=![]()
此时,称![]() 为近似值
为近似值![]() 的绝对误差限,简称误差限或精度。有了绝对误差限就可以知道
的绝对误差限,简称误差限或精度。有了绝对误差限就可以知道![]() *范围为:
*范围为:![]() -
-![]() ≤
≤![]() *≤x+
*≤x+![]()
即![]() *落在区间
*落在区间![]() 内。在工程应用上,常常采用
内。在工程应用上,常常采用![]() *=
*=![]() ±
±![]() 来表示近似值
来表示近似值![]() 的精度或精确值
的精度或精确值![]() *的所在范围。
*的所在范围。
绝对误差是有量纲的。例如,用毫米刻度的直尺去测量一个长度为![]() *的物体,测得其近似值为
*的物体,测得其近似值为![]() =
=![]() (mm)。这样,虽然不能得出准确值
(mm)。这样,虽然不能得出准确值![]() *的长度是多少,但从这个不等式可以知道
*的长度是多少,但从这个不等式可以知道![]() *的范围是:
*的范围是:![]() *<
*<![]() *必在区间[14.5,15.5]内。
*必在区间[14.5,15.5]内。
2 相对误差与相对误差限
用绝对误差来刻画一个近似值的精确程度是有局限性的,在很多场合中它无法显示出近似值的准确程度。如测量
定义![]() 的相对误差,即:
的相对误差,即:![]() =
=![]()
由于精确值![]() *一般无法知道,因此往往取
*一般无法知道,因此往往取![]() =
=![]() 作为近似值
作为近似值![]()
的相对误差。
类似于绝对误差的情况,若存在正数![]() ,使得:
,使得:
![]()
则称![]() 为近似值
为近似值![]() 的相对误差限。相对误差是无量纲的数,通常用百分比表示,称为百分误差。
的相对误差限。相对误差是无量纲的数,通常用百分比表示,称为百分误差。
例
根据绝对误差限的概念,第一个数据D的精确度比第二个数据d的精确度差,但由于![]() ,
,![]()
根据相对误差限的概念,第一个数据D的精确度比第二个数据d的精确度高,这个结果比较合理,与人们的常识一致。所以,在分析误差时,相对误差更能刻画误差的特性。
1.2.4 有效数字
为了能给出一种数的表示法,使之既能表示其大小,又能表示其精确程度,于是需要引进有效数字的概念。在实际计算中,当准确值![]() *有很多位数时,我们常按四舍五入的原则得到
*有很多位数时,我们常按四舍五入的原则得到![]() *的近似值
*的近似值![]() 。
。
例
取一位数时![]() =3, 有
=3, 有![]()
取三位数时![]() =2.72, 有
=2.72, 有![]()
取五位数时![]() =2.7183,有
=2.7183,有![]()
由以上分析可知,按四舍五入原则不管取几位小数得到的近似值,其绝对误差都不超过末位数的半个单位。
下面我们将四舍五入抽象为数学语言,进而引进“有效数字”的概念。
定义![]() 是准确数
是准确数![]() * 的近似数,且
* 的近似数,且![]() ,那么我们就说,用近似数
,那么我们就说,用近似数![]() 表示
表示![]() *时,准确到非零数之间的一切数字都叫做有效数字,并把有效数字的位数叫做有效数位,它反映了
*时,准确到非零数之间的一切数字都叫做有效数字,并把有效数字的位数叫做有效数位,它反映了![]() 近似
近似![]() *的精确程度。
*的精确程度。
也可用文字叙述如下:若近似值![]() 的绝对误差限是某一位的半个单位,就称
的绝对误差限是某一位的半个单位,就称![]() “准确”到这一位,且从该位到
“准确”到这一位,且从该位到![]() 的第一位非零数字共有n位,则称近似值
的第一位非零数字共有n位,则称近似值![]() 有n位有效数字,或者说
有n位有效数字,或者说![]() 精确到该位。实际上,用四舍五入方法取得准确数
精确到该位。实际上,用四舍五入方法取得准确数![]() *的前n位(不包括第一位非零数字前面的零)数,作为它的近似数
*的前n位(不包括第一位非零数字前面的零)数,作为它的近似数![]() 时,
时,![]() 就有n位有效数字,其中每一个数字(包括后面的零)都叫做
就有n位有效数字,其中每一个数字(包括后面的零)都叫做![]() 的有效数字。
的有效数字。
引入有效数字概念后,我们规定所写出的数都应该是有效数字,且在同一计算问题中,参加运算的数,都应该有相同的有效数字。在上面的例子中,![]() 有1位有效数字,
有1位有效数字,![]() 具有3位有效数字,而
具有3位有效数字,而![]() 具有5位有效数字。
具有5位有效数字。![]() 分别具有6,5位有效数字。
分别具有6,5位有效数字。
如何描述有效数字?(一般情况下在计算机中数往往规格化,故有必要考察规格化数。)一般地,任何一个精确值![]() *经四舍五入后,所得到的近似值
*经四舍五入后,所得到的近似值![]() 都可写成十进制浮点数表示形式:
都可写成十进制浮点数表示形式:![]() =±
=±![]() 。其中,
。其中,![]() 且
且![]() 都是0~9中的任一整数,
都是0~9中的任一整数,![]() 称为尾数。
称为尾数。![]() 用于确定小数点位置,指数m称为阶码。因此,一个浮点数包含尾数和阶码两部分。
用于确定小数点位置,指数m称为阶码。因此,一个浮点数包含尾数和阶码两部分。
当![]() 的绝对误差满足:
的绝对误差满足:![]() =
=![]() 时,则称近似值
时,则称近似值![]() 具有n位有效数字。可以证明有效数字的两种定义方式是等价的。
具有n位有效数字。可以证明有效数字的两种定义方式是等价的。
在例![]() =3=0.3×10,有
=3=0.3×10,有![]() ×10(1-1),所以
×10(1-1),所以![]() 有1位有效数字,或者说
有1位有效数字,或者说![]() 精确到个位;
精确到个位;![]() =2.72=0.272×10, 有
=2.72=0.272×10, 有![]() =0.5×10(1-3),则
=0.5×10(1-3),则![]() 具有3位有效数字,或者说
具有3位有效数字,或者说![]() 精确到0.01,
精确到0.01,![]() =2.7183=0.27183×10,有
=2.7183=0.27183×10,有![]() =0.5×10(1-5),则
=0.5×10(1-5),则![]() 具有5位有效数字,或者说
具有5位有效数字,或者说![]() 精确到0.0001。
精确到0.0001。
由此可见,如果用浮点数![]() 表示某个数据的近似值时,当阶码m一定时,有效数字位数n越多,其绝对误差越小。
表示某个数据的近似值时,当阶码m一定时,有效数字位数n越多,其绝对误差越小。
有效数字不但给出了近似值的大小,而且还给出了它的绝对误差限。例如有效数字15.28,0.283×10-2,0.2830×10-2的绝对误差限分别为:0.5×10-2,0.5×10-5,0.5×10-6。
必须注意,在有效数字的记法中有效数字尾部的零不能随意省去,以免损失精度。例如,对于一个精确值![]() *=3.51499962(吨),其两个近似值
*=3.51499962(吨),其两个近似值![]() =3.515(吨) 与
=3.515(吨) 与![]() =3.515000(吨)的近似程度是完全不同的,
=3.515000(吨)的近似程度是完全不同的,![]() 精确到0.001(精确到公斤),有四位有效数字,而
精确到0.001(精确到公斤),有四位有效数字,而![]() 精确到0.000001(精确到克),有七位有效数字。
精确到0.000001(精确到克),有七位有效数字。
还需特别指出的是,一个准确数字的有效数字应当说有无穷多位,例如1/2=0.5不能说只有1位有效数字。
例:设![]() ,它的两个近似值
,它的两个近似值![]() 和
和![]() 分别有3,4位有效数字。
分别有3,4位有效数字。
有效数字与相对误差有如下关系:
定理![]() 具有n位有效数字,则其相对误差限为:
具有n位有效数字,则其相对误差限为:![]() 。
。
证明 由![]() =±
=±![]() 。其中,
。其中,![]() 且
且![]() 都是0~9中的任一整数,得:
都是0~9中的任一整数,得:![]() ,所当
,所当![]() 有
有![]() 位有效数字时,
位有效数字时,![]() ,则:
,则:![]()
![]() 。
。
证毕。
可见有效数字的位数越多,相对误差限就越小,即近似值的有效位数越多,用这个近似值去近似代替准确值的精度就越高。
例![]() 近似值的相对误差小于1%,问至少取几位有效数字?
近似值的相对误差小于1%,问至少取几位有效数字?
解 ![]() 的近似值的首位非零数字是4,则有:
的近似值的首位非零数字是4,则有:
![]()
解之得n>2,故取n=3即可满足要求。也就是说只要![]() 的近似值具有3位有效数字,就能保证
的近似值具有3位有效数字,就能保证![]() ≈4.47的相对误差小于1%。
≈4.47的相对误差小于1%。
定理![]() 的相对误差限
的相对误差限![]() ,则
,则![]() 至少具有
至少具有![]() 位有效数字。
位有效数字。
证明
若![]() 有相对误差限:
有相对误差限:![]() ,则:
,则:
![]()
![]()
![]()
因此![]() 至少有
至少有![]() 位有效数字,证毕。
位有效数字,证毕。
有效数字的位数可以刻画近似数的精确度(有效数字的位数越多,绝对误差限和相对误差限就越小) 。绝对误差与小数后的位数有关,相对误差与有效数字的位数有关。
1.2.5 数值计算的误差估计
数值计算中误差产生与传播的情况非常复杂,参与运算的数据往往都是些近似值,它们都带有误差。而这些数据的误差在多次运算中又会进行传播,使计算结果产生一定的误差,这就是误差的传播问题。
以下介绍利用函数的Taylor公式来估计误差的一种常用方法。
设二元可微函数![]() 中的自变量
中的自变量![]() *1,
*1,![]() *2相互独立,又
*2相互独立,又![]() 1,
1,![]() 2是自变量
2是自变量![]() *1,
*1,![]() *2的近似值,则
*2的近似值,则![]() 的近似值
的近似值![]() 。
。
将函数![]() 在点(
在点(![]() 1,
1,![]() 2)处作泰勒展开,并略去其中的高阶无穷小项,即可得到y*的近似值y的绝对误差的估计式为:
2)处作泰勒展开,并略去其中的高阶无穷小项,即可得到y*的近似值y的绝对误差的估计式为:
![]()
![]() =
=![]()
≈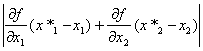
=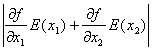
其中两个偏导数应该是在点(![]() 1,
1,![]() 2)处的值。
2)处的值。
近似值y的相对误差的估计式为:
![]()
=![]()
以上式子中的![]() 及
及![]() 分别为各个
分别为各个![]() 对
对![]() 的绝对误差和相对误差的增长因子,分别表示绝对误差和相对误差经过传播后增大或缩小的倍数。
的绝对误差和相对误差的增长因子,分别表示绝对误差和相对误差经过传播后增大或缩小的倍数。
由以上两个公式,很容易导出两个近似值和与差的绝对误差和相对误差的估计式: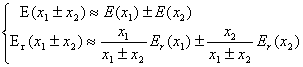
对于绝对误差有:![]() 。即和与差的绝对误差不大于各绝对误差之和。
。即和与差的绝对误差不大于各绝对误差之和。
对于相对误差,考虑最坏的情况是所有相对误差同号,当![]() 时,可得:
时,可得:
![]()
即和的相对误差不超过各单项中的最大相对误差。
同理可得两个近似值之积、商绝对误差和相对误差的估计式:
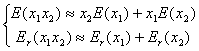
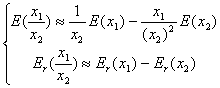
近似值x的绝对误差和相对误差的估计式,也可用微分的形式近似表示。绝对误差![]() ,相对误差
,相对误差![]() 。并有如下结论:
。并有如下结论:
1 和的绝对误差:d(x+y)=dx+dy。因此,和的绝对误差限![]() (x+y)≤
(x+y)≤![]() x+
x+![]() y。
y。
2 和的相对误差:![]()
=![]()
对相对误差可作一些讨论:
⑴ 当xy<0时,必有:![]() 或
或![]()
这时对于很小的相对误差dlnx或dlny可能导致很大的相对误差dln(x+y),特别是x+y≈0时,可能使dln(x+y)相当大,因此在近似计算中应当努力避免相近的两个数相减,避免小的数作分母,这是减小误差的一个原则。
为此在x接近于零时,常作变换:![]()
当x充分大时,常作变换:![]()
⑵ 当xy>0时,必有:![]() 或
或![]() ,则:
,则:
![]()
即和的相对误差不超过相对误差之和进而有:![]() (x+y)≤
(x+y)≤![]() x+
x+![]() y。
y。
同时还可推出:![]()
![]()
+![]()
![]()
![]()
因此,表明同号两数和的相对误差(限)不超过这两数相对误差(限)的最大者。
特别地,当![]() 时,
时,![]() ,则:
,则:![]() 。
。
因此,当同号二数的绝对值相差很大时,其和的相对误差约等于绝对值大者的相对误差。
3 积的绝对误差 d(xy)=xdy+ydx,积的相对误差dln(xy)=dlnx+dlny。
特别地,dlnxn=ndlnx。
4 商的绝对误差:![]()
商的相对误差:![]()
多个数值相乘除时,其相对误差等于各乘数和除数的相对误差的和与差,例:
![]()
5
函数的相对误差:![]()
对于多元函数![]() ,它的绝对误差:
,它的绝对误差:
![]()
![]()
它的相对误差:![]() 。
。
最后指出,在由误差估计式得出绝对误差限和相对误差限的估计时,由于取了绝对值并用三角不等式放大,因此是按最坏的情形得出的,所以由此得出的结果是保守的。事实上,出现最坏情形的可能性是很小的。因此近年来出现了一系列关于误差的概率估计。一般来说,为了保证运算结果的精确度,只要根据运算量的大小,比结果中所要求的有效数字的位数多取1位或2位进行计算就可以了。
1.2.6 算法的数值稳定性
所谓算法,不仅是单纯的数学公式,而是对一些已知数据按某种规定的顺序进行有限次四则运算,求出所关心的未知量的整个计算过程。解决一个计算问题往往有多种算法,其计算结果的精度往往大不相同。原因是初始数据的误差或计算中的舍入误差在计算过程中的传播,因算法不同而相异。一个算法如果输入数据有误差,而在计算过程中舍人误差不增长,则称此算法是数值稳定的,否则,称此算法为不稳定的。
在构造算法时,应构造数值稳定的,尽量避免误差的危害。算法数值稳定通常有以下几条原则:
1)要防止“大数吃小数”。在数值计算中,参加运算的数有时数量级相差很大,而计算机的字长有限,加减法在向上对阶、运算,再四舍五入时,小数被吃掉。故在多数做和时,可将同号数按从小到大的顺序来计算。
2)要避免二相近的数相减。两个相近数相减会引起有效数字的严重损失,从而导致相对误差的增大。要避免这种情况,通常可采用数学方法将相应的计算公式转化为另一个等价的计算公式来计算。例如,x充分大时,计算
![]()
时,![]() 与
与![]() 很接近,直接计算会造成有效数字的严重损失,可将原式化为一个等价公式
很接近,直接计算会造成有效数字的严重损失,可将原式化为一个等价公式
![]()
来计算,以减少误差。
3)要避免绝对值很小的数作除数。绝对值很小的数作除数会直接影响计算结果的精度,这是由
![]()
可见,当|y|充分小时,![]() 可能会变得很大。避免这种情况的方法,往往可用化其为其他等价形式来处理,例如,当x接近于0,将
可能会变得很大。避免这种情况的方法,往往可用化其为其他等价形式来处理,例如,当x接近于0,将![]() 转化为等价式
转化为等价式![]() 来计算,可避免这种情况发生。
来计算,可避免这种情况发生。
4)要减少运算次数,避免误差积累。减少运算次数,能减少舍入误差及其传播环节。如对多项式
![]()
的计算,直接计算需做![]() 次乘法,而采用秦九绍算法,只需进行n次乘法。
次乘法,而采用秦九绍算法,只需进行n次乘法。
5)要控制舍入误差的积累和传播。如一定积分递推公式,初值的舍入误差在计算过程中迅速传播,而用逆推公式,则成为数值稳定的算法。